Gérer les imprimantes sous Gnome sans droit admin
Sur la Debian de ma maman, il y a un truc embêtant : elle ne peut pas gérer ses problèmes d’imprimantes toute seule. Par défaut, il faut être administrateur de …
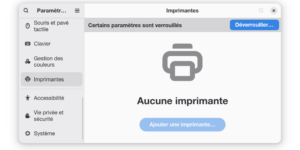
Sur la Debian de ma maman, il y a un truc embêtant : elle ne peut pas gérer ses problèmes d’imprimantes toute seule. Par défaut, il faut être administrateur de …

Après avoir fait deux articles sur la reconnaissance vocale sous Android et la synthèse vocale sous Android, passons à la reconnaissance vocale sous Linux. J’ai trouvé un logiciel sur Flatpak …

Après la synthèse vocale sur Android, passons à la reconnaissance vocale (speech to text ou STT). Toujours à la recherche d’une solution libre et respectueuse de l’intimité, on m’a conseillé …

Je partage ici une trouvaille pour faire de la synthèse vocale (text to speech ou TTS) libre sur Android pour, par exemple, le guidage audio sur OrganicMaps. Voici le lien …

DNS est le service annuaire servant à résoudre les noms de domaines. Par exemple si vous cherchez à résoudre l’adresse de SciHub https://sci-hub.se selon le service DNS que vous utilisez …

Je voulais avoir 2 versions de Debian sur mon ordi bien séparées et chiffrées. Ce n’est pas visiblement un cas « prévu » par l’installeur. Voici donc ma configuration, elle n’est pas …
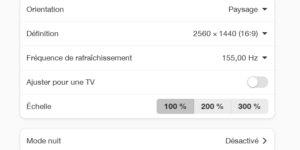
Si vous achetez un écran récent, vous aurez probablement un écran haute résolution. Tellement haute résolution par rapport à la taille physique de votre écran que pour ne pas que …

J’ai acheté une montre connectée Pinetime. Je vous livre ici un compte rendu. Prix La montre est vendue 27$ sur le site officiel. Mais il faut rajouter les frais de …
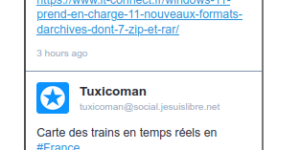
Voici un petit plugin pour avoir afficher le fil de vos messages Mastodon sur un site web. Par exemple sur ce blog, dans la barre latérale: Le code se trouve …

Voici un guide pas à pas pour créer une machine virtuelle Windows 11 (nouvelle installation) avec Gnome-Boxes sous Linux (j’ai utilisé Debian 12 pour être précis). Je pensais au départ …