Ça fait un petit moment que je travaille sur mon projet de moteur de recherche anonymisé. Je l’utilise depuis quelques mois et il est maintenant prêt à entrer en production et découvrir le monde !
Je l’ai appelé Mysearch. Il s’agit d’une application qui va faire office de proxy entre vous et les grands moteurs de recherche du web. Ce n’est donc pas un moteur de recherche à proprement car il n’a pas de crawler propre, mais plutôt un intermédiaire anonymisateur, comme DuckDuckGo. Voila à quoi ca ressemble:
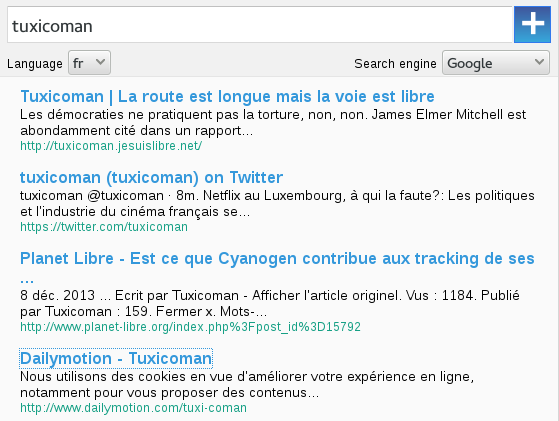
J’ai mis à disposition mon instance de Mysearch sur https://search.jesuislibre.net si vous voulez tester.
Concrètement, Mysearch va anonymiser vos recherches :
- en masquant votre IP originelle vis à vis du moteur de recherche
- en vous proposant une page web propre expurgée de tout moyen de tracking (cookie vous identifiant même si vous n’avez pas de compte, lien unique pour chaque résultat permettant de savoir quel résultat vous avez choisi , scripts obscurs utilisés pour vous traquer, mot-clés de votre de recherche transmis au résultat choisi, enregistrement de votre recherche à votre profil, etc…) dont sont truffés les pages de résultats des moteurs de recherche commerciaux (Google, Bing, Yahoo, etc…)
- du coup, la page web est bien mois lourde et économise votre bande passante (11ko versus 830ko pour une recherche simple sur Google !)
- en supprimant les publicités qui squattent la place du premier résultat
L’intérêt par rapport à DuckDuckGo:
- la pertinence des résultats de Google (DuckDuckGo achète ses résultats à Yandex qui renvoie des résultats pourris sur les requêtes avec plusieurs mots clés)
- qui peut vérifier ce que fait DuckDuckGo de vos données personnelles? C’est une entreprise américaine, donc soumise aux desiratas de la NSA sans qu’elle puisse communiquer dessus.
- pas de publicité à la place du premier résultat. Car DuckDuckGo a comme Google, un business model basé sur la publicité (vous ne croyez quand même pas que c’était gratuit hahaha…)
Pour l’instant les moteurs de recherches intégrés à Mysearch sont Google, Google Image, Google Vidéo, Wikipedia et Openstreetmap. On peut choisir la langue dans laquelle on veut les résultats. Le design de la page web est approprié à une utilisation tant sur smartphone que sur grand écran.
Le sources de Mysearch se trouvent sur la forge Codingteam
J’ai créé un paquet Debian pour installer simplement Mysearch chez vous. Mysearch est lancé en tant que service automatiquement au démarrage.Il utilise un utilisateur spécifique « mysearch » pour la sécurité de vos données persos. Vous pouvez arrêter le service en lançant en root : # service mysearch stop
Vous pouvez y accéder à l’adresse http://localhost:60061 (encore un chiffre de plus pour le port et je pouvais écrire GOOGLE en leet speak)
Salut et merci pour ton boulot, je teste ça de suite :)
J’ai essayé DuckDuckGo mais je n’ai pas adhéré en particulier à cause des résultats qui sont en dessous de ce que Google offre.
MySearch me semble donc un outil intéressant à tester et avec le paquet Debian, ça va être très simple à faire !
Donc merci.
Les premiers essais (via ton instance) sont sont très prometteurs
Question de non-spécialiste : Y aurait-il un moyen de se l’héberger sur un mutualisé OVH ?
Très sympas, j’aurais du temps, je ferais un petit addon d’un scrolling vertical avec autoload ajax.
Là pour le moment tu peux parcourir les pages, mais tu ne peux pas revenir en arrière et surtout au niveau visibilité c’est un peu limité.
Mais mis à part ça c’est simple, clean, rapide … impressionnant boulot.
C’est cool ça… GG ^^
C’est un peu comme ce que j’ai fait avec googol ( https://github.com/broncowdd/googol ) mais en python…
Plus il y aura d’alternatives au flicage de Google, mieux ce sera ! Continue ! Je shaare de suite ;-)
Bonjour,
question bête mais comment fais-tu pour masquer l’ip du client auprès Google ? le proxy MySearch étant soit installé en local ou sur un serveur (auto-hébergé ou non) donc il sortira avec son ip publique qui sera, de toute façon, visible par google. Ou bien ai-je raté quelque chose ?
Merci
Salut,
très intéressant !
Pourrais-tu comparer avec Seeks ? (http://seeks.fr/) Lui cache notre adresse IP, non ?
Et quels sont tes plans maintenant ?
N’y a-t-il pas une alternative pour se passer de google ?
@Tepee : Je ne sais pas trop ce que te propose OVH. Mais en gros il faut pouvoir exécuter lancer Twisted déja.
@arf : c’est vrai que c’est classe le scrolling mais je ne savais pas comment le faire. J’aimerai aussi ne pas trop surcharger la page (seul l’affichage des vignettes nécessite Jquery pour l’instant)
@Comète : L’IP que recevra Google est celle de l’ordinateur où est installé Mysearch.
Déja, ce n’est plus forcément celle de l’ordinateur où tu consultes le web (donc Google n’a plus l’IP (et la geolocalisation approchée) de ton smartphone, laptop, etc… On pourrait faire passer la requête de Mysearch par un VPN ou fédéraliser les installations de Mysearch pour qu’elles s’échangent les requêtes et résultats pour noyer le poisson.
Salut Tuxicoman. J’ai me le concept . Franchement les réponses de google sont généralement les plus pertinentes pour mes recherches par rapport aux autres moteurs de recherche.
Ma question: est-il possible d’installer MySearch dans un VPS facilement (avec https+ nginx) ?
@groov : Seeks fait aussi office de proxy. Mais je ne comprenais pas son code. Je préfère le python. Seeks n’a pas pour but de garantir l’anonymat ou la confidentialité des requêtes. Par exemple, les vignettes des images sont téléchargés depuis leur emplacements d’origine, ce qui envoie votre IP et un referrer qui (qui contient l’URL avec votre requête) au serveur de Google.
Salut,
beau boulot,
je viens d’utiliser http://www.tobtu.com/customsearch.php?s= pour en faire ma recherche par défaut sur Firefox
Merci
C’est chouette, bonne initiative! Mais je tique sur ça:
« » »
Concrètement, Mysearch va anonymiser vos recherches :
en masquant votre IP originelle vis à vis du moteur de recherche
…
« » »
Dire que c’est anonymisé est un raccourci trompeur. C’est anonymisé si tu utilises l’instance mysearch de quelqu’un d’autre. Si tu installes ce truc chez toi et que ça n’est utilisé que par toi: Google verra toutes tes recherches provenant de ton IP publique (celle de ton FAI, ou celle de ton serveur dédié) qui t’est associée personnellement.
Bravo pour ce projet. J’ai une question: pourquoi les liens des résultats sont une redirection et pas le lien direct? N’est-ce pas contraire à la volonté de ne pas pister les visiteurs?
Et une remarque de fond:
N’y a-t-il pas des solutions plus durables qui consisteraient à indexer le Web nous-mêmes pour se passer des sociétés commerciales pour la recherche Web?
Je pense au projet Yacy, projet de recherche P2P.
Ses résultats ne sont pas extraordinaires pour l’instant (inférieurs à Google et à DuckDuckGo) mais il ne demandent qu’à être améliorés par la communauté. Un tel moteur est libre et anonyme.
Je fais tourner une node chez moi avec en priorité de l’index français, vous pouvez tester ici: http://109.190.109.228:8090/
Le portail qui répartit les requêtes aux pairs est ici http://search.yacy.net/
Le site du projet est là: http://yacy.net/fr/index.html
Le forum international est là: http://www.yacy-forum.org/
Installez Yacy, crawlez et partagez avec le reste du réseau!
@man : J’ai peur que ton « Custom Search Creator » ne serve à rien. Lorsque tu feras une recherche, c’est google qui est contacté directement
@sto: lorsque tu cliques sur un lien, ton navigateur va envoyer une requête au serveur qui héberge le lien en question avec :
– l’url de la page que tu cherches sur ce serveur
– l’url de la page d’où tu vient (referrer)
– les caractéristiques de ton navigateur (user-agent)
– les cookies correspondant au serveur s’il y en a enregistré sur ton navigateur
– ton IP, pour que le serveur sache où renvoyer la réponse à la requête
Hors dans le cas des moteurs de recherche, ce qui se fait couramment, c’est de mettre le mot clé que l’on cherche dans l’url. C’est pratique car on peut forger une url qui contient déja la requête à la main, mais c’est aussi obligatoire pour ajouter le moteur de recherche à Firefox par exemple. Or, je n’ai pas envie que le site sur lequel je vais aller sache les mot clés que j’ai cherché pour y arriver.
Donc pour cela, je fais un redirection vers une page temporaire dont l’url est « nettoyée » avant de rediriger le navigateur sur le véritable lien. Tu peux regarder dans le code.
Je sais ca parait contre nature au début mais en fait bien logique. C’est grace à cette trace que les logiciels de stats pour site web savent quels mots clés ont été utilisés pour venir visiter les sites web. Maintenant Google ne donne plus de lien direct non plus et fait une redirection mais avec des ID uniques pour vous pister plus. C’est pas le même objectif bien que le même moyen technique soit employé. En plus, pour Google, c’est doublement intéressant. Le site web destinataire ne peut plus savoir ce que cherchait l’internaute mais GoogleAnalytics lui le sait très bien et peut revendre cette info au site web….
Un peu de doc si tu veux :
https://www.facebook.com/notes/facebook-engineering/protecting-privacy-with-referrers/392382738919
http://fr.wikipedia.org/wiki/R%C3%A9f%C3%A9rant
@sto: à propos de Yacy, j’ai essayé mais ca consommait bcp de CPU pour des résultats beaucoup moins pertinents que ceux de Google. L’intérêt du moteur de recherche, c’est de trouver ce que l’on cherche et Seeks, DuckDuckGo et Yacy ne me donnaient pas satisfaction.
Il y aussi le problème du langage. Je ne suis pas fan de Java.
@tuxicoman
merci pour les précisions concernant le système de referer, je ne voyais pas les choses de ce point de vue-là. cela signifie quand même qu’avec la redirection, si j’utilise ton instance de MySearch, je devrai te faire confiance car tu pourras regarder sur quel site je suis allé, même si tu ne le fais pas en l’état actuel du code.
À vrai dire, si cela ne me convient pas, je peux toujours installer ma propre instance de MySearch.
pour Yacy, j’ai dû lire ton article il y a longtemps et l’oublier entre temps. mea culpa. c’est vrai que c’est lourdingue. et le java, ça ne fait pas vraiment rêver.
ta solution est un très bon compromis anonymat/performance, mais elle ne me semble viable que si peu de gens l’utilisent. sinon Google réagirait et verrouillerait davantage son système.
je suis un brin idéaliste et crois qu’un système à la Yacy, indépendant des gigantesques bases de Google/Yahoo,/Yandex est possible. la recherche distribuée est un sujet de recherche actuel (et ça a l’air plutôt gratiné!).
Connais-tu Faroo? C’est du P2P commercial, mais ça mérite le détour pour saisir le concept.
Merci de tenir ce blog intéressant, à bientôt!
@sto: oui je pourrais logger ton IP, ta recherche et les liens sur lesquels tu cliques. Tout comme DuckDuckGo. On ne peut pas avoir confiance si l’intelligence est dans le serveur. D’où le fait que je propose le code source et de quoi l’installer simplement. Dans le futur, peut être que je pourrais faire de l’onion routing entre instances Mysearch.
Mysearch interagit avec Google par l’interface web. Donc c’est difficile pour Google de me bannir comme ça. Il pourrait seulement bannir mon IP mais ca bannirait aussi tous ceux qui sont derrière mon IP publique et il y a du monde :-) Ca leur ferait une mauvaise pub. De plus si plusieurs personnes font tourner Mysearch, Google va t il bloquer toutes les IPs ?
Je viens de tester Faroo mais il ne me trouve même pas : http://www.faroo.com/#q=tuxicoman&s=1&l=fr&src=web
@sto : je viens de rajouter Yacy à la liste des moteurs de recherche utilisable par Mysearch. Comme tu peux le voir, les résultats ne sont pas très probants
@tuxicoman : en changeant le URL SEARCH par https://search.jesuislibre.net/mysearch?more_results=2&backend=Google&locale=en&q={searchTerms} » ( bien que le site n’est pas forcement pérenne) dans ce cas je devrait ne pas passer par google ?
Pas mal, tu compte le laisser comme tels , ou l’amélioré, filtres, fonctionnalités etc ?
@man : MySearch est compatible OpenSearch. Donc tu peux ajouter facilement le moteur de recherche à ton navigateur (Ex: Firefox ou Firefox mobile)
@tuxicoman: je sais pas comment j’ai pu raté ça … merci encore c’est beaucoup mieux
Ping Recherche Web sous ANONYMAT | Pearltrees
Bien pour Yacy ! C’est vrai qu’il n’est pas encore utilisable:
– on ne peut pas encore choisir la langue des résultats
– les résultats sont encore mauvais. Il faut plus de monde qui indexe le web (fçais -bcp d’allemands et russes !)
@Tuxicoman: pourrais-tu te fendre d’un post technique expliquant ton implémentation, avec un peu de code python/twisted ? (Ou alors rajoute de la doc dans le code.) Ça m’intéresse un max, merci !
Salut Tuxicoman,
Merci de contribuer au développement d’un internet plus libre et plus respectueux. En lisant les articles sur Mysearch, j’ai réfléchi à une manière d’augmenter l’anonymat. J’ai imaginé un site qui irait piocher ses résultats sur un instance de Mysearch parmi plusieurs.
Imaginons qu’il y a 100 personnes qui hébergent Mysearch. Ces 100 personnes pourraient utiliser une autre page qui irait interroger l’une des 100 instance de Mysearch aléatoirement.
Intérêts :
— Si une personne modifie le code d’une instance Mysearch, il ne reçoit qu’une requête sur 100 en moyenne.
— Chaque recherche passe par une IP différente chez Google. (puisqu’on utilise des instances différentes)
Négatif :
— Un intermédiaire de plus.
Qu’en pense-tu ?
Tuxicoman,
Je trouve mysearch top.
Je l’ai testé et j’ai fais cela :
> Mise en place du .py sur mon serveur.
> J’ai monté un tunnel SSH depuis mon laptop vers mon serveur.
> J’appelle le moteur via : localhost:port
Dans l’état actuel des chose :
> Les requêtes sont elles chiffrées ?
> Quelle est l’ip que Google voit ?
Merci pour ces précisions et encore bravo
@laifen : Google voit l’IP de la machine où est installé Mysearch uniquement. La communication entre Mysearch et Google est chiffrée en interrogeant Google par https. Entre Mysearch et ta machine client, ca dépend de comment tu te connectes (en ssh t’es peinard dans ton cas)
Je vais publier un tuto pour accéder à mysearch à travers Apache.
@esprit: j’ai réfléchi à cela aussi un peu. Voici où en est ma réflexion (dans le cas où l’on ne voudrait pas faire confiance à un serveur Mysearch tiers) :
Tu dois quand même faire confiance au premier noeud, c’est lui qui te présente l’interface de Mysearch dans ton navigateur. Mais ca peut être MySearch installé en local sur ton PC.
Le deuxième noeud et les suivants ne devraient pas avoir ta confiance. Ils pourraient altérer les résultats. Le deuxième noeud pourrait en outre associer la recherche à ton IP. Donc il faudrait passer qu’ils transmettent juste ta recherche à Google mais que seul Google puisse déchiffrer les données. En gros tunneler de l’HTTPS. Je ne sais pas si c’est faisable facilement ni comment éviter que ca devienne un tunnel à tout faire.
Arrivé là, on peut retourner le problème et se dire que si la connexion entre le premier noeud et Google passe par Tor, on a quelque chose d’équivalent. Donc pourquoi pas faire un réseau Tor entre toutes les instances de Mysearch? Mais comment limiter le flux à uniquement des recherches originaires d’autres instances Mysearch?
@tuxicoman
Merci pour tes explications.
Si Google voit l’IP de mon serveur sur lequel est installé mysearch, y a pas de soucis qu’il puisse exploiter quoi que ce soit d’autres qui sont installé dessus ?
Merci
@laifen : Non, Mysearch envoie une requete HTTP/web comme n’importe quel navigateur l’aurait fait. Je ne comprends pas bien ta dernière question.
@tuxicoman
En fait non, ma question était sans importance, donc on peut oublier :)
Par contre j’ai une autre question, dans le début de ton article, tu dis :
> « en masquant votre IP originelle vis à vis du moteur de recherche »
Mais hier tu as dis :
> « Google voit l’IP de la machine où est installé Mysearch uniquement »
Je ne comprend pas trop :/
Merci pour tes précisions.
J’attend avec impatience ton tuto pour utiliser mysearch à travers Apache :]
Ping OpenSSL et la vérification du domaine dans les certificats | Tuxicoman
Sur Debian Wheezy, après: apt-get install python2.7 python-twisted python-jinja l’installation de mysearch échoue avec:
dpkg -i Téléchargements/mysearch_1.8-1_all.deb
Sélection du paquet mysearch précédemment désélectionné.
(Lecture de la base de données… 158295 fichiers et répertoires déjà installés.)
Dépaquetage de mysearch (à partir de …/mysearch_1.8-1_all.deb) …
dpkg: des problèmes de dépendances empêchent la configuration de mysearch :
mysearch dépend de python-pyasn1-modules ; cependant :
Le paquet python-pyasn1-modules n’est pas installé.
mysearch dépend de python:any (<= 2.7.5-5~) ; cependant :
dpkg: erreur de traitement de mysearch (–install) :
problèmes de dépendances – laissé non configuré
Des erreurs ont été rencontrées pendant l’exécution :
mysearch
Le paquet python-pyasn1-modules ne peux être installé:
apt-get install python-pyasn1-modules
Lecture des listes de paquets… Fait
Construction de l’arbre des dépendances
Lecture des informations d’état… Fait
Aucune version du paquet python-pyasn1-modules n’est disponible, mais il existe dans la base
de données. Cela signifie en général que le paquet est manquant, qu’il est devenu obsolète
ou qu’il n’est disponible que sur une autre source
E: Le paquet « python-pyasn1-modules » n’a pas de version susceptible d’être installée
Est-ce que mysearch requiert une version supérieure de Debian ? Merci.
Qu’est ce qui est indiqué après « mysearch dépend de python:any (<= 2.7.5-5~) ; cependant :" ? J'utilise Debian Stable (Jessie)
Il me dit ça:
dpkg -i Téléchargements/mysearch_1.8-1_all.deb
(Lecture de la base de données… 158335 fichiers et répertoires déjà installés.)
Préparation du remplacement de mysearch 1.8-1 (en utilisant …/mysearch_1.8-1_all.deb) …
Dépaquetage de la mise à jour de mysearch …
dpkg: des problèmes de dépendances empêchent la configuration de mysearch :
mysearch dépend de python-pyasn1-modules ; cependant :
Le paquet python-pyasn1-modules n’est pas installé.
mysearch dépend de python:any (<= 2.7.5-5~) ; cependant :
dpkg: erreur de traitement de mysearch (–install) :
problèmes de dépendances – laissé non configuré
Des erreurs ont été rencontrées pendant l’exécution :
mysearch
Ce qui est en contradiction avec le message d’hier …
Mais comme python-pyasn1-modules n’existe pas sur Wheezy, je pense que c’est mort.
Effectivement, il faudrait passer en jessie mais vu le plantage avec systemd la dernière fois que j’ai essayé, je ne suis pas chaud !
Primeiramente congratulações pela postagem.
Eu nem conhecia esse blog Mas pelo pouco que já li fiquei impressionado.
É Parabéns achar conteúdo de qualidade assim na web. Abraço! http://www.sexe-toys.org/que-e-exatamente-a-flora-vaginal-e-como-cuida/