Comme vous devriez le savoir, Google et bien d’autres sociétés ne tarissent pas de moyens pour collecter sur vous les moindres détails de votre vie. On peut au moins compter :
- IP
- liens de redirection avec ID personnalisée (avec Firefox, faites clic droit -> examiner sur un lien de résultat Google pour voir cette merde)
- cookie de Google.com mais aussi des services qui partagent leur données avec Google.com (Youtube, GooglePlus ,etc..)
- Flash variable, javascript et autre technique utilisant les fonctionnalités avancées de votre navigateur.
- HTTP referrer / user agent qui contient votre requête et des données sur votre configuration (OS, navigateur, résolution d’écran)
- services Google intégrés aux sites web que vous visitez après (Youtube, GoogleAnalytics, GooglePlus, etc…)
Beaucoup d’utilisateurs, réticents à ce qu’une société (ou la NSA pas loin derrière) puisse concentrer autant d’informations sur chaque humain se sont tourné vers DuckDuckGo comme moteur de recherche.
DuckDuckGo promet l’anonymisation de vos recherches. Mais quelle garantie offre ce discours de plus que le « Don’t be evil » de Google d’hier? Je n’ai aucun moyen de vérifier ce que fait DuckDuckGo de mes données, ni de vérifier si la NSA n’a pas un accès aux données de DuckDuckGo. De plus DuckDuckGo, utilise lui aussi un modèle économique basé sur la publicité pour financer ses coûts (Les fameuses « Instant answers » qui s’affichent avant tous les résultats et qu’on en peut pas désactiver) donc, ça va sentir le roussi bientôt pour avoir des réponses claires et pertinentes à ses requêtes.
En plus de cela, les résultats de DuckDuckGo sur plusieurs mots sont bien plus mauvais que ceux de Google.
Ma solution à cela est d’avoir son propre portail de recherche en local sur son ordinateur qui va faire le travail d’anonymisation pour nous. Voici à quoi ca ressemble :
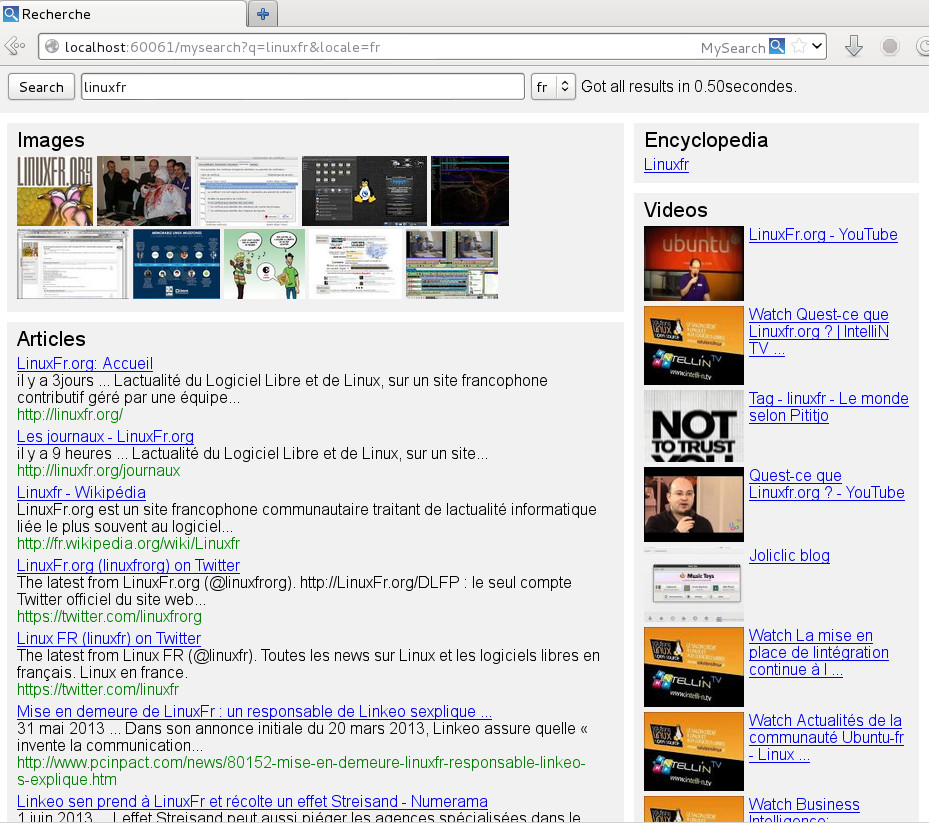
Sous le capot, il s’agit d’un petit programme local en Python/Twisted/Jinja qui va interroger différents moteurs de recherche par leur interface web (Startpage, Google, Wikipedia, etc…) et formater les résultats retournés dans une page web locale après anonymisation des liens.
Le formatage est fait par une simple feuille de style CSS. Facile de changer la mise en page.
Les requêtes aux différents moteurs de recherches sont dans des classes Python distinctes et il est facile de rajouter une recherche pour Bing, Yahoo, whatever…
Avantages :
- supprime toutes les publicités
- pertinence des résultats en provenance de ses moteurs de recherche préféré
- aucun cookie enregistré par les moteurs de recherche sur votre navigateur. (Donc pas de tracking par votre compte Google, Facebook, etc..)
- user-agent anonyme
- supprime les liens de redirection personnalisés qui nous identifient
- supprime le http-referrer lorsque l’on clique sur un lien de résultat
- permet de styliser l’apparence des résultats (ex: voir les résultats texte, vidéo, image et wikipedia en une seule page par exemple)
- permet de choisir sa source de recherche (Google, Ixquick; DuckDuckGo, Bing, etc…) sans changer de mise en page. (WIP)
- permet de choisir son pays de recherche (google.com, google.fr, etc…) sans changer de mise en page. En effet les résultats sont fortement différents selon la localisation de la requête.
- peut s’utiliser par l’interface OpenSearch (ajout à la liste des moteurs de recherches de Firefox par exemple)
Il reste encore un point à régler:
- anonymiser son IP lors de la collecte de résultats de recherche. Là c’est plus compliqué, il faudrait utiliser un proxy entre les utilisateurs du système pour brouiller les pistes. Ou n’utiliser que Startpage et DuckDuckGo comme source de resultats si on a confiance en eux pour ne partager notre couple IP/requête. Ou utiliser Tor.
Le dépôt du code est ici sous licence AGPL v3.
Pour tester chez vous :
$ sudo apt-get install python python-twisted python-jinja2 subversion
$ svn co http://svn.codingteam.net/mysearch
$ python mysearch/mysearch.py
Rendez vous sur http://localhost:60061
Comme DuckDuckGo au départ, ce système n’est pas un moteur de recherche classique avec un vrai crawler qui irait indexer toutes les pages du web. C’est trop coûteux. C’est donc pour l’instant un « meta-moteur » et les résultats proviennent de requêtes effectuées sur les moteurs existants.
J’ai essayé auparavant Yacy qui a un crawler mais ca consommait vraiment beaucoup de ressources (cpu, disque, réseau) pour des résultats pas forcément pertinents vu la faible puissance de calcul des utilisateurs du système.
J’ai essayé Seeks il y a longtemps, le projet est il mort? Le dernier post sur le site de projet donne des liens complètement cassés. Quoi qu’il en soit, le temps de réponse était long et je ne pouvait pas mixer les résultats aussi facilement que dans mon petit script Python.
Sur le modèle économique de la chose, on pourrait dire que je vole le travail effectué par Google en pompant ses résultats sans lui donner la monnaie de la pièce (je n’affiche pas ses publicités ni lui donne d’information personnelle). DuckDuckGo achète ses résultats à Yahoo et Bing (pour ceux qui pensaient que c’était gratuit) et bien entendu Google ne va pas lui vendre les siens.
Néanmoins, on peut aussi voir cela comme un post-traitement en local des données, au même titre que Adblock filtre la pub dans les pages web en local.
Ou aussi que si Google diffuse bien des extraits de mes pages (images, texte) sans que je ne puisse le contraindre à diffuser l’intégralité de mes pages, je peux bien faire de même et afficher des extraits de ses pages également. Si il n’est pas content, il n’a qu’à bannir mon IP (on va rire vu le nombre de machines qui risque que d’être derrière :D )
Wow, excellent! C’est toi qui a codé? j’essaie ça tout de suite…
Ouaip c’est moi qui ait tout fait. Mais c’est pas long à faire.
Hop, encore un truc que je vais garder sous la main et sans doute porter vers php (pour que je puisse l’héberger chez mon hébergeur). Merci :-)
Houla, une version php ça m’intéresserait vachement aussi ça, mon hébergeur ne supporte pas le python…
Enfin quelqu’un de critique face à DDG, merci !
Concernant tor, c’est une bonne idée, mais google bloque les requetes tor. Je ne sais pas pour les autres.
Super. Ça fonctionne plutôt bien. Un premier petit bug. Lorsqu’on change de pays/langue, fr à en par exemple, ça change bien les résultats provenant de google, mais les liens wikipedia ne sont pas corrects. C’est toujours fr.wikipedia.org bien que ça renvoie vers un titre d’article de en.wikipedia.org
Tiens, je pense que je vais tester tout ça ^^
Pour le fait de repomper google, je ne me suis pas gêné pour googol ^^ qui part du même constat sur un principe identique mais en php ;)
Ta version semble toutefois bien plus complète du fait qu’elle interroge plusieurs moteurs.
@Clem : C’est corrigé ! Merci pour le test.
@Bronco: Comment tu fais pour supprimer le referer?
J’ai trouvé de la doc sur https://www.facebook.com/notes/facebook-engineering/protecting-privacy-with-referrers/392382738919
et j’ai implémenté la méthode de Google finalement : http://codingteam.net/project/mysearch/browse/templates/redirect.html
Ta version ne semble pas passer par une page intermédiaire mais je n’ai pas trouvé de solution qui marche bien sans.
Superbe article et excellent travail !
Rien que le fait d’empêcher Google et compagnie de savoir sur quel résultat je clique est une grosse avancée !
Et merci beaucoup pour l’éclairciseement sur DDG que j’utilisais depuis un certain temps les yeux fermés.
Je vais tester ça de suite !
À+
@Tuxicoman: Le projet de Bronco se trouve là :
https://github.com/broncowdd/googol
Tu auras donc ta réponse pour supprimer le referer.
Sinon ton projet est intéressant, je pense qu’il faudrait par contre le porter en php si tu veux faciliter son adoption.
Je pense également qu’il faudrait améliorer la visibilité des résultats dans ta feuille de style CSS (ne pas faire qu’un seule rectangle gris pour tout les résultats mais un rectangle pour chaque résultat).
Librement,
Salut,
J’ai voulu tester mais au lancement ça plante sur « ImportError: No module named markupsafe » : http://haste.zertrin.org/ticibuvepi.py
J’ai juste installé python-twisted et pas Jinja2 au niveau système puisque le Readme dit que normalement c’est déjà bundled…
(Debian wheezy, python 2.7.4).
Ai-je raté quelque chose ?
Ok en vérifiant les dépendances de python-jinja2, y’a bien python-markupsafe, qui lui n’est pas bundlé dans mysearch.
Il faut donc pour le moment obligatoirement installer python-markupsafe (ou python-jinja2 tant qu’on y est).
Peut-être penser à corriger le Readme.txt en conséquence et cet article aussi ;)
Bon maintenant c’est parti pour tester ! Désolé pour le double post :)
Bon comme on dit, jamais 2 sans 3 :)
Après test en plaçant mysearch derrière un proxy apache mes premières impressions sont très positives :)
Si l’on apprécie le support d’OpenSearch, cela ne fonctionne cependant que si l’on installe Mysearch sur le localhost ;) Dans mon cas je l’héberge sur un serveur distant et y accède via un sous-domaine, donc évidemment http://localhost:60061/ mon navigateur local ne trouve pas. Je ne sais pas s’il serait facile d’adapter la balise <link rel… facilement pour ce genre de situations où l'on installe pas Mysearch localement.
Sinon je vais essayer de l'utiliser comme moteur principal ces prochains jours pour voir s'il y a d'autres petites remarques qui me viennent.
En tout cas, merci déjà d'avoir codé ceci et de partager :)
J’avais pas vu que Jinja était packagé dans Debian Stable. Du coup, j’ai supprimé le bundle de la librairie et mis celle-ci en dépendance.
@Zertrin : je viens de modifier le code pour l’herberger sur ton serveur distant. Dans le fichier mysearch.py, tout en haut tu mets ton nom de domaine ou ton IP externe et ca devrait rouler !
(supprime et réinstalle le moteur de recherche dans firefox aussi)
Haha… Marrant de voir que beaucoup de monde croit encore que DDG est un moteur américain qui ne flirte pas avec la NSA…. :)
Je viens d’essayer sous manjaro:
File « mysearch/mysearch.py », line 98
print « Timer %s : %.2f » % (self.__class__, timer)
^
SyntaxError: invalid syntax
Excellente idée! ddg est très decevant sur la qualité des résultats, et aucune garantie a par les croire sur parole. Google ne se gène pas pour nous profiler, ne nous génons pas a respecter ses conditions d’utilisation…
Question au passage, on ne pourrait pas faire la meme chose avec un script greasemonkey? ca permettrait de rendre l’outil disponible au plus grand nombre, directement integré dans le navigateur.
Hello,
Je viens de tester ton meta moteur.
et je l’ai mis dérriere un proxy apache2 en TLS sans trop de souci…
sauf:
j’ai du modifié index.html dans le template pour remplacer le
par
et cela afin que je puisse utiliser le script dans un sous répertoire (en l’occurence /mysearch/… qui est un proxy vers le serveur python).
Sinon je pense que la possibilité de voir plus de résultats serait aussi une bonne idée ;)
Fréd.
@Eco : ton erreur vient du fait que tu utilises python3, il faut python2.
Je pense que tu devrais pouvoir faire un truc du genre : « pacman -Suy python2 » et ensuite « python2 mysearch/mysearch.py »
Salut Tuxicoman,
Je viens de jeter un oeil aux modifs que t’as apportées, cependant la solution proposée n’est pas vraiment idéale à mon avis.
Avec ta modif, l’adresse de binding (reactor.listenTCP) et l’adresse renvoyée dans opensearchdescription.xml sonc forcément les mêmes, or ce n’est pas toujours le cas.
Notamment on ne peut pas supposer que mysearch va être la seule application à écouter sur le port 80 ou 443, d’où l’idée de le proxyfier via Apache (ou Nginx ou autre). Autrement dit, le fait que mysearch écoute sur localhost:60061 n’est pas un souci, au contraire :) Je n’ai pas besoin de changer l’adresse de binding.
Par contre il faut un moyen de configurer quelque part que la vraie adresse publique où l’on peut accéder à MySearch n’est pas la même adresse que celle utilisée pour ouvrir la socket TCP. Et c’est cette adresse qui est à renvoyer dans le opensearchdescription.xml.
Si j’ai un peu plus de temps je verrai pour proposer un patch, mais j’avoue que j’utilise pour la première fois SVN… (j’ai directement commencé à utiliser des DVCS comme Mercurial et Git ^^ les VCS centralisés c’est pas un peu has been ? :P )
Je trouve ce projet super intéressant.
Je l’ai testé et ça me plait bien.
J’ai un serveur perso.
Est ce que ton logiciel est adapté pour être mis en place sur un serveur et être utilisé tous les jours ou bien ton logiciel est t’il plutôt préférable de l’utiliser comme un proxy en local ?
Merci
Je pense en local c’est préférable. Je n’ai pas encore eu de vrai retour sur la sécurité de la chose.
Bon projet, si je pouvais le mettre en place sur mon NAS (synology) ça serait encore mieux, faut que je regarde ça.
En tout cas merci car les solutions type Yacy en java c’est bien gentil mais ça c’est bien trop gourmand.
Je suis en train de travailler sur l’interface pour la rendre pratique sur smartphone autant que sur 27″
Super projet, Tuxicoman !
Je viens de le découvrir, génial, merci pour ce boulot et ce partage !
Cela dit, j’aurais souhaité pouvoir afficher un peu plus de résultats….J’ai regardé dans le code (bien que je ne sois vraiment pas spécialiste en python, et je ne vois pas ou changer cela…(modifier les valeurs de 10 en 50 dans backends.py et dans les fichiers entries n’a eu aucun effet, même en effaçant les fichier pyc…)).
Y’a-t’il une ruse que je n’aurais pas trouvé?
Merci d’avance si tu as un moment pour me répondre…
C’est parce que la page Google que j’intérroge ne me donne que 10 résultats. J’utilise un page mobile pour économiser en bande passante et faciliter le parsing.
Si tu veux plus de résultats il modifier le backend pour qu’il parse plusieurs pages.
OK, merci pour ta réponse Tuxicoman,
je me replongerai dedans quand j’aurai un moment…:-)
Ping Mysearch version 1.0 et paquet debian | Tuxicoman
Ping Mysearch version 1.0 et paquet debian | Tuxicoman
Bonjour,
Je viens d’essayer d’installer une copie sur mon poste. Deux problèmes :
-le premier est qu’il y a deux dossiers mysearch,
-le second est que j’ai des erreurs au lancement de l’application.
python mysearch/mysearch/mysearch.py
Traceback (most recent call last):
File « mysearch/mysearch/mysearch.py », line 32, in
import backends
File « /home/xxxx/mysearch/mysearch/backends.py », line 30, in
import onion
File « /home/xxxx/mysearch/mysearch/onion.py », line 33, in
import ext_libs.service_identity as service_identity
File « /home/xxxx/mysearch/mysearch/ext_libs/service_identity/__init__.py », line 11, in
from . import pyopenssl
File « /home/xxxx/mysearch/mysearch/ext_libs/service_identity/pyopenssl.py », line 12, in
from pyasn1_modules.rfc2459 import GeneralNames
ImportError: No module named pyasn1_modules.rfc2459
Ne codant pas en python, je n’ai pas trop saisi ce que ça raconte. Apparemment, il n’y aurait pas de module pyasn1_modules.rfc2459, c’est ça ???
Comment je fais pour le charger ???
j’ai installé en ligne de commande et aussi avec le paquet .deb puis ouvert le port 60061 sur la box et le pare-feu du PC mais ça ne fonctionne pas.
Je ne sais plus comment j’avais fait il y a longtemps mais c’était bon.
A l’aide :)
Ping Qwant et la publicité – Tuxicoman